
The History and Future of Compute
History, Limitations, Trends and Hardware Developments

👋 Hi there! My name is Felix and welcome to Deep Tech Demystified! Once a month I will publish topical overviews or deep-dives about Deep Tech topics that excite me. I will try to make the writings comprehensible and accessible for people from all backgrounds, doesn’t matter if it’s business, engineering or something completely else.
🧮 The History of Compute
Computing techniques have been used for a long time and were the building blocks for many revolutionary shifts advancing humanity. The abacus as the earliest computation device dates back to more than 2000 BC and is still in use today in some places of the world. What started out as a simple tool for addition and substraction evolved into more advanced and complex concepts to represent logic and thus enable more than just simple addition or substraction. In the 19th century, Charles Babbage laid the foundations for modern computing with his mechanical computing device, the so called Difference Engine, consisting of gears, levers and other mechanical components to tabulate polynomial functions.

This device later evolved into the Analytical Engine, an electromechanical computation device being able to represent logic and conditional loops that also incorporated memory functionality. This device can be seen as the first general-purpose computer, i.e. the first device useful for more than a pre-defined purpose. Advancements in electromechanical computing by IBM in the 1930s and 1940s with its Harvard Mark I further improved performance and reliability. The next big step in computing was enabled by switching from electromechanical to electronic computing with vacuum tubes as fundamental technology. The diode is the simplest form of a vacuum tube (although nowadays they are semiconductor based), allowing current to flow in a defined direction under certain circumstances. For more information about this forgotten piece of technology, see here. Vacuum tubes allowed for way faster switching speeds compared to mechanical counterparts, thus improving computational performance again.
In 1947 a fundamental phaseshift occured, that revolutionized our way of life in many ways. John Bardeen, Walter Brattain and William Shockley successfully engineered a Nobel Prize-winning invention, the transistor, at Bell Labs, a research laboratory of AT&T. The transistor is a semiconductor, that controls current in switching current on or off and amplifying it. The transistor replaced vacuum tubes in almost all applications, offering smaller sizes, lower power consumption and greater reliability and also offering much more potential for further miniaturisation, thus enabling more logic functionality on a given surface. This fundamental building block enabled Jack Kilby and Robert Noyce, back then at Texas Instruments, to combine multiple transistors on a single chip, the first integrated circuit (IC), another Nobel Prize-winning invention. Robert Noyce, nicknamed as “the mayor of Silicon Valley” and Co-Founder of Intel, then developed the first microprocessors in the early 1970s, a single-chip central processing unit (CPU). Subsequently, the era of the personal computer had begun. The first commercially sold CPU, the Intel 4004, consisted of 2300 transistors.

The current Apple M3 chip encompasses between 25 and 93 billion transistors, depending on the model at hand. This corresponds to a nearly 40 million-fold increase in transistor count over a period of roughly 50 years. This exponential increase was already predicted by Gordon Moore in 1965, where he projected that transistor count would double approximately every two years due to progress in miniaturization. For the original paper see here. Please note, that the following figure by Our World in Data uses a logarithmic scale, showcasing the constant growth rate corresponding to exponential growth. If you’re interested how this accurate projection by Gordon Moore and its manifestation in reality massively impacted our lives ranging from military to smartphones and beyond, I can wholeheartedly recommend you the book Chip War by Chris Miller. It is one of the best books on semiconductors, very accessible to non-technical people and a must read for anyone working in tech.
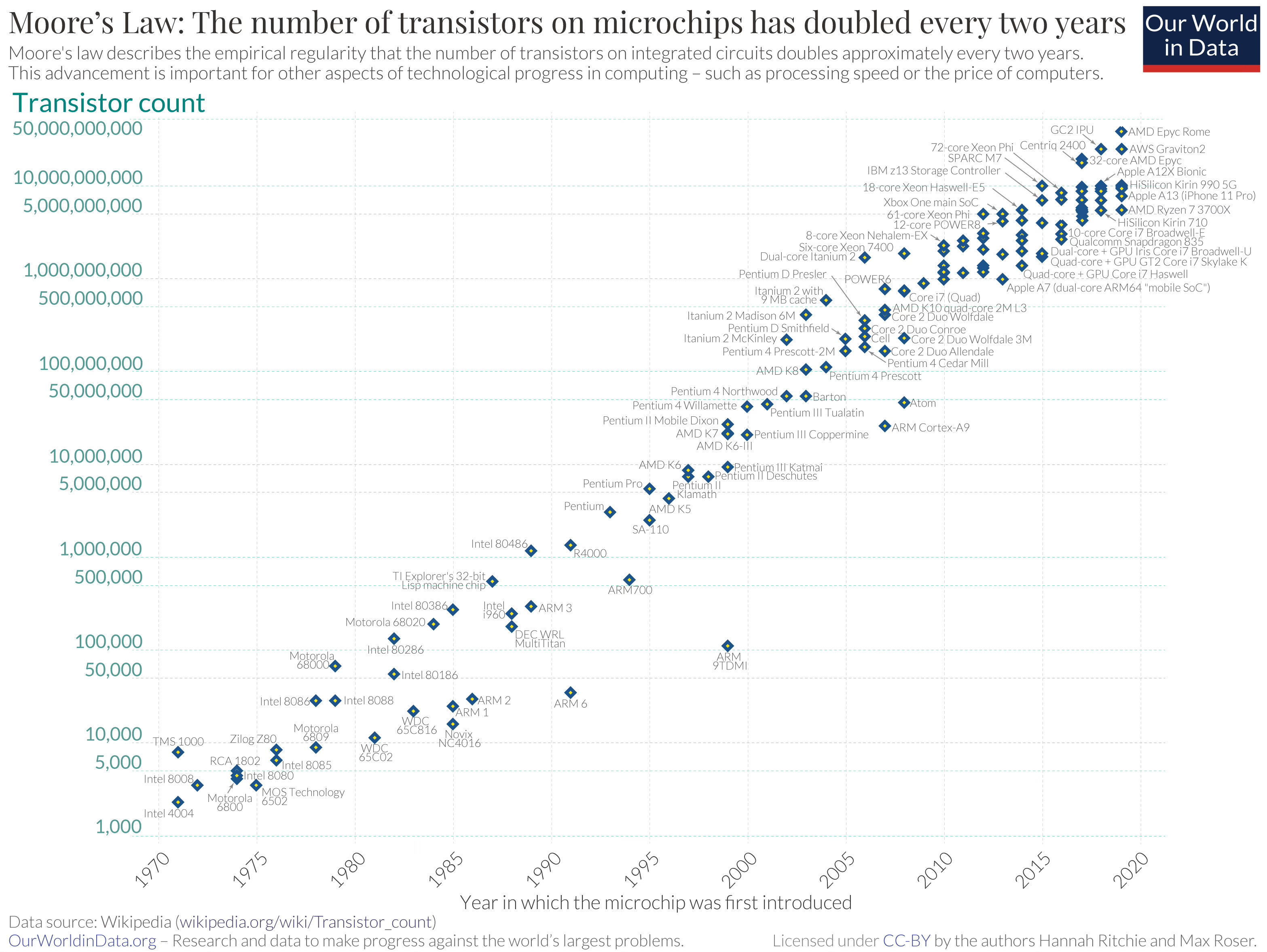
To come back to the topic and to set the stage for the future of compute: What would you guess is the main driver in performance increase in chips when you look at the figure above? Yes, you have (most likely) guessed right! The increase in transistor count on a chip, fuelled by every-progressing miniaturization. So what would happen, if you could no longer decrease transistor size, because the transistor is in the sizes of just a few atoms?
Good read: Computerhistory.org
Limitations of the Compute Stack
📈 Moore’s Law
Transistor sizes shrinked remarkably over the last decades from 10,000nm for the Intel 4004 to today’s 48nm for the Apple M3, which is essentially only a few atoms wide. But shrinking indefinitely is impossible due to quantum effects that will appear at atomic scale, impacting reliability and controllability of the components, besides the increasing heat generated by such densely packed structures. Also, from a manufacturing perspective, the process (lithography - light that will print a pattern onto the substrate) becomes increasingly costly and difficult. I will not go into greater detail how the process works as one could fill pages just talking about the complex supply chains necessary to build the machines. If it interests you look up ASML, they are the (European) monopoly behind this technique. Hint: they recently published their gross margin for Q4 2023 as of 51,3%, which is quite telling alone. Although there exist different approaches to combat the issue of miniaturization limitations, like using multiple cores in the processing unit or specialized processors like graphics processing units (GPUs), the gist of this is, that the main source of performance improvements, namely shrinking transistor size, is coming to its physical limits and will sooner than later become impossible.
🐏 Memory Bandwidth
An important part of the compute stack refers to the memory. Both memory and the CPU form the so called von-Neumann architecture described by John von Neumann in 1945. The CPU represents the logic behind calculations done by a computer, while the memory stores the underlying data and instructions that are feed into the CPU for calculation. While the microprocessor performance and its transistor density improved tremendously as elaborated above, the same can not be said about memory performance. This is referred to as “processor-memory performance gap”, because of a yearly processor performance increase of 60% compared to less than 10% for memory bandwidth.
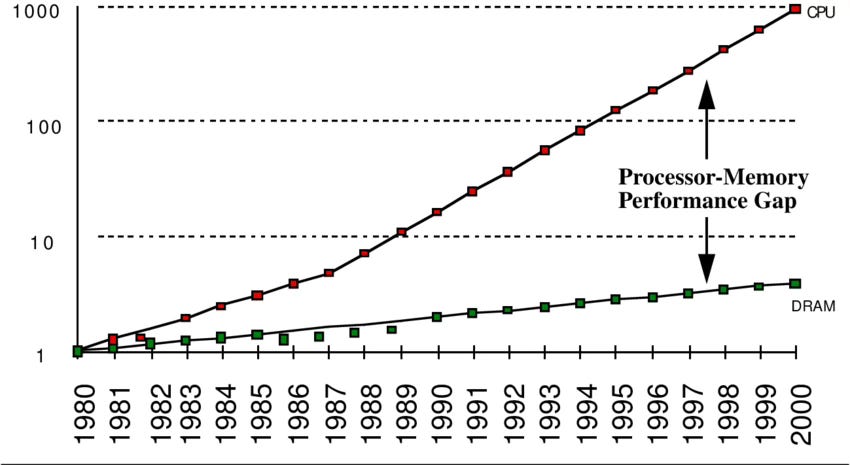
This results in memory performance lagging behind the microprocessor improvements and thus limiting the actual processing in the von-Neumann architecture. Imagine a swimming pool where the water level represents the effective usage of your CPU. Your swimming pool has an open drain the size of a large pizza where water escapes, representing the data and instructions it can process and thus “clear”. At the same time you’re filling the pool with a watering can you would normally use to water your small cactus that needs a few drops of water once a week, representing your memories ability to feed the CPU with workload. Your CPU would never even come close to full usage, thus wasting lots of potential.
Both of the limitations discussed above limit further exponential performance improvements in the current approaches to compute. Simultaneously, those limitations face (exponentially) growing demands for compute performance induced by AI and data.
Macro Trends Affecting Compute
🤖 Artificial Intelligence
AI is currently one of the most trending topics that has evolved from a small open-source research community to mass-adoption with the launch of ChatGPT, setting a new record for reaching 1 million users after only five days. The launch not only fascinated a lot of techies like me but also sent shockwaves through the business world. According to a study by the CFO Magazine for example, around 72% of business leaders want an AI adoption in their business within the next three years. Simultaneously, AI models are growing exponentially, requiring ever more compute power for training and inference. Note: FLOPs refers to floating-point operations per second, a measure to express the number of floating-point arithmetic calculations systems can perform on a per-second basis.

Thus, it is unsurprising to see that the data centers providing the necessary compute consume already about 3% of our global electricity and are estimated to reach 4% by 2030. In 2021 researchers from Google and University of California, Berkley estimated the carbon emissions of GPT-3’s training at around 550 tons of CO2. And the carbon cost will continue to increase. This is also one of the major reasons why Climate Tech investors should really care about compute!
💾 Data
Data is the new gold. Thus, businesses try to digitize everything that is digitizable, to make sense of, and optimize their own processes or enable new business models. This fuelled for example the IoT sector to grow from roughly 3 to 17 billion connected devices since 2015 and is expected to grow another 16% till 2027. As a result it is projected that the volume of data will exceed 180 zettabytes by 2025. This would correspond to 180 billion one terabyte hard drives to store all of the data in the world. Interestingly, as of today, only 10% of the data is unique, meaning 90% of the existing data is just a result of copy&paste.
To sum all of this up, we have seen remarkable progress in classical computing over the last decades. But due to the limitations of physics, it is unlikely that this progress will prevail for the next decades. At the same time mega trends like AI are continuously demanding more powerful hardware to work. Thus, to keep up the momentum of progress we need to see new approaches to compute. This is a tremendous challenge with severe implications for our economy and environment, but also a wonderful opportunity for growth and innovation that excites me as an investor and engineer at heart every day.
Hardware Developments in Compute
🧠 Neuromorphic Computing
Neuromorphic computing, as the name suggests it, takes inspirations from the workings of the brain. The brain needs very little energy and works at comparable low temperature of 37°C while being able to rival frontier technology at the supercomputer level. For example, the Hewlett Packard Enterprise Frontier needs around 20 MW of power with a dimensional footprint of 680 m² to reach around 1 exaFLOP of computing performance. The human brain reaches the same performance while simply requiring the power of a fridge lightbulb at 20 W with a significantly lower dimensional footprint. Think of a small bird, being able to navigate in unknown environments at flight speeds up to 20 km/h with a brain the size of a raisin, outperforming our best approaches at computer vision with state-of-the-art hardware on a drone. Thus, it is easy to see why such a design holds many promises to solve compute in certain tasks.
But how does it conceptually work? Neuromorphic architectures consist of artificial neurons and synapses. Those structures store the information that is learnt while at the same time processing the data. Just how we train neural network (NN) models in deep learning and store the trained information in synaptic weights. But in this case in hardware and not a software that is emulated through processors. Thus, we can natively, meaning without having to simulate a NN on CPUs or GPUs, execute calculations. In that sense, neuromorphic architectures differentiate from the von-Neumann architectures since memory and processor are no longer separated, but a single structure. There is also no synched clock frequency at which computation occurs, but rather event driven processing. Thus, this approach not only eliminates bottlenecks at the intersection of memory and processing unit, but also has the potential to significantly improve energy efficiency. Thus, neuromorphic architectures are a promising candidate for edge applications that work well with NN algorithms. Like computer vision or speech recognition.

Some well-known corporates in that area: Intel and IBM.
Some well-known start-ups in that area: Synthara, Innatera and Axelera AI.
Good reads:
stateofthefuture.xyz by Lawrence Lundy-Bryan @ Lunar Ventures
2022 roadmap on neuromorphic computing and engineering by Christensen et al.
💡 Photonic Computing
Photonic computing makes use of photons and its advantageous physical properties, opposed to existing electron-based digital computing. If you think back to your physics lectures, you might remember, that photons don’t have a mass. As a result, photons don’t generate heat through friction, compared to electrons in transistor structures that are ever densely packaged. Also, photons travel at the speed of light, enabling high-speed data transfer with low latency. The downside of all of this is, that because of the properties of photons, it is also way more difficult to contain them. To make photonics work, efficient photodetectors and modulators are necessary to keep speed high and power consumption low. Main challenges remain for example in miniaturization and until then the theoretical advantage of photons will stay theoretical. While it may take some time until we see commercially available optical chips, the potential is very clear for AI and AI inference. Matrix multiplications, as well as linear algebra operations are quickly performed in the optical domain and thus well suited for high-performance or even edge computing.
What is more realistic in the mid-term, are photonic interconnects to enable data transfer at the speed of light between so called chiplets. Chiplets are different types of semiconductors that are integrated onto a more complex chip. Those chiplets might have different functions, like a memory chiplet or a processor chiplet. To enable communication between those densely packed chiplets, high-speed and energy efficient photonic connections are the perfect match. Tech giants like Intel, AMD and Nvidia already use chiplet structures for their advanced consumer and enterprise products. It should be noted that it is desirable to carry out as much computation as possible in the optical domain to avoid bottlenecks in the conversion from the optical to the electrical domain and vice versa, or even bottlenecks in computation in the electrical domain itself.
Some well-known start-ups in that area: Black Semiconductor and NcodiN.
📱 Application-Specific Integrated Circuits (ASICs) and RISC-V
ASICs are the least disruptive approach to computing covered here and they date back to the origins of IC design at Fairchild Semiconductor. While CPUs and GPUs are intended for general-purpose computing and flexible regarding applications, ASICs follow the principles of specialized IC design for a specific task. Due to the pressure of performance increases and the increasingly diminishing improvements in transistor density this is a viable approach. This might be particularly useful for large scale deployments of e.g. specific AI tasks. In combination with open-source RISC-V instruction set architecture and field programmable gate arrays (FPGAs) for prototyping the development is quiet cheap and might even get cheaper in the future. Note: FPGAs are off-the-shelf hardware, that can be reconfigured by the buyer to meet specific use case requirements.
Some well-known start-ups in that area: Graphcore and Codasip.
⚛ Quantum Computing
I will keep this paragraph very short, since quantum computing should (and will) be a post of its own. Quantum computing fundamentally differs from classical bit-based computing. Classical computing is based on the deterministic principles of classical mechanics, meaning that if you give it certain data and fire up a program the results produced will be the same every time. Quantum computers on the other hand are made up of qubits and devices for manipulating those qubits, equivalent to a classical computers CPU and memory, but with its own spin to it. To keep it short, classical computing comes to its limit if the problem to be solved involves combinatorial explosion, meaning a problem in which a small increase in number of inputs results in exponential increase in processing time, like traveling salesman optimization or protein folding. In that sense, quantum computing can be seen complementary to classical computing. If you want to learn more about it, I can recommend you Quantum Computing for Dummies by William Hurley, the CEO of Strangeworks. It not only teaches you how quantum computing works, but also how little physics you know as an engineer.

{kind=link}
{kind=link}
And on that high note I will conclude my first attempt at writing. If you liked it let me know. And the more so if you didn’t like it and have constructive criticism that will help to improve my next attempts. What to expect in the future? I will try to semi-regularly cover topics in the Deep Tech & Climate Tech domain that excite me but will stick in the near-term to computing related topics. The next post will most likely be a deep dive into neuromorphic computing, as it currently excites me the most.
I am also actively looking into the computing space as investor, so if you are a founder that wants to chat, please do reach out to me (felix@playfair.vc). Cheers!