
Is DNA the Future of Data Storage?
The current state of storage technology and why we need DNA to scale

👋 Hi there! My name is Felix and welcome to Deep Tech Demystified! Once a month I will publish topical overviews or deep-dives about Deep Tech topics that excite me. I will try to make the writings comprehensible and accessible for people from all backgrounds, doesn’t matter if it’s business, engineering or something completely else.
🙋🏻♂️ A Short Preface
Hi there, glad you’re interested in the sixth edition of Deep Tech Demystified! This blog posting will cover DNA as an approach to data storage and where our current storage technology stack is heading in this age of information accumulation. Following I will briefly give reasoning for my own thesis on DNA as potential storage medium of the future. Feel free to reach out if you want to discuss!
💡The Need for Storage Innovation
It is not a novel insight that in today’s day and age data is omnipresent and plays a somewhat important role in everyone’s life. For some their most prized data are the photos of the last family reunion and for others it’s their business’ data that allows them to build products on top of it. Going beyond all the different use-cases though, it seems to be against human nature to get rid of “old” data. We continue to hoard piles of data drives in ever increasing data centres and started calling it at some point (very intellectually) big data, because - well, because it just got pretty big.

Jokes aside, our desire to store every bit of information will be an economical, technical and sustainable challenge at some point, as our collected data is piling up exponentially. With the current growth-rate of data production (at 20-40% CAGR) and comparably lower storage density (performance) improvements of existing technologies (< 8% for hard disk drives and continually decreasing) we will run out of storage capacity in a few years down the line. Production of data will simply outpace production of storage. As a result we will not only need to scale up capacity exponentially, but also manufacturing capabilities, to keep up. This might be technically feasible to some point, but surely not economically reasonable. As an additional data point (🙂), to emphasize the magnitude of this dilemma, Gartner predicts a shortfall of 2/3! in enterprise storage capacity by 2030.
To cut this intro short: we need innovation in storage, otherwise there won’t only be hard competition for the most valuable data but also for the physical medium to store it. But is DNA the problem solver? Let’s find out!
🧬 Storing Data in DNA
Scientists and engineers oftentimes draw inspiration from nature to derive novel solutions for pressing problems. The solution to storage might be one of the most obvious contenders, hiding in plain sight. DNA is and has been nature’s means of choice to pass on complex information in extremely compact manner since more or less forever. The currently oldest find of DNA dates back 2 million years and has enabled scientists to reconstruct a forgotten and ancient ecosystem in Greenland. But how does DNA work and what makes it an interesting contender to revolutionize data storage?
🔬 DNA Storage in Theory
Naturally, DNA (deoxyribonucleic acid) occurs as double-stranded DNA (dsDNA) in the form of a double helix, composed of two linear strands twisted together. This makes the DNA very robust but also allows for correcting errors in the DNA. The strands consist of backbones out of sugar as side rails and complementary chemical nucleic acids (bases) on each strand, forming a connection across strands. The bases and their order store and express the genomic information and are called Adenine (A), Thymine (T), Cytosine (C) and Guanine (G).
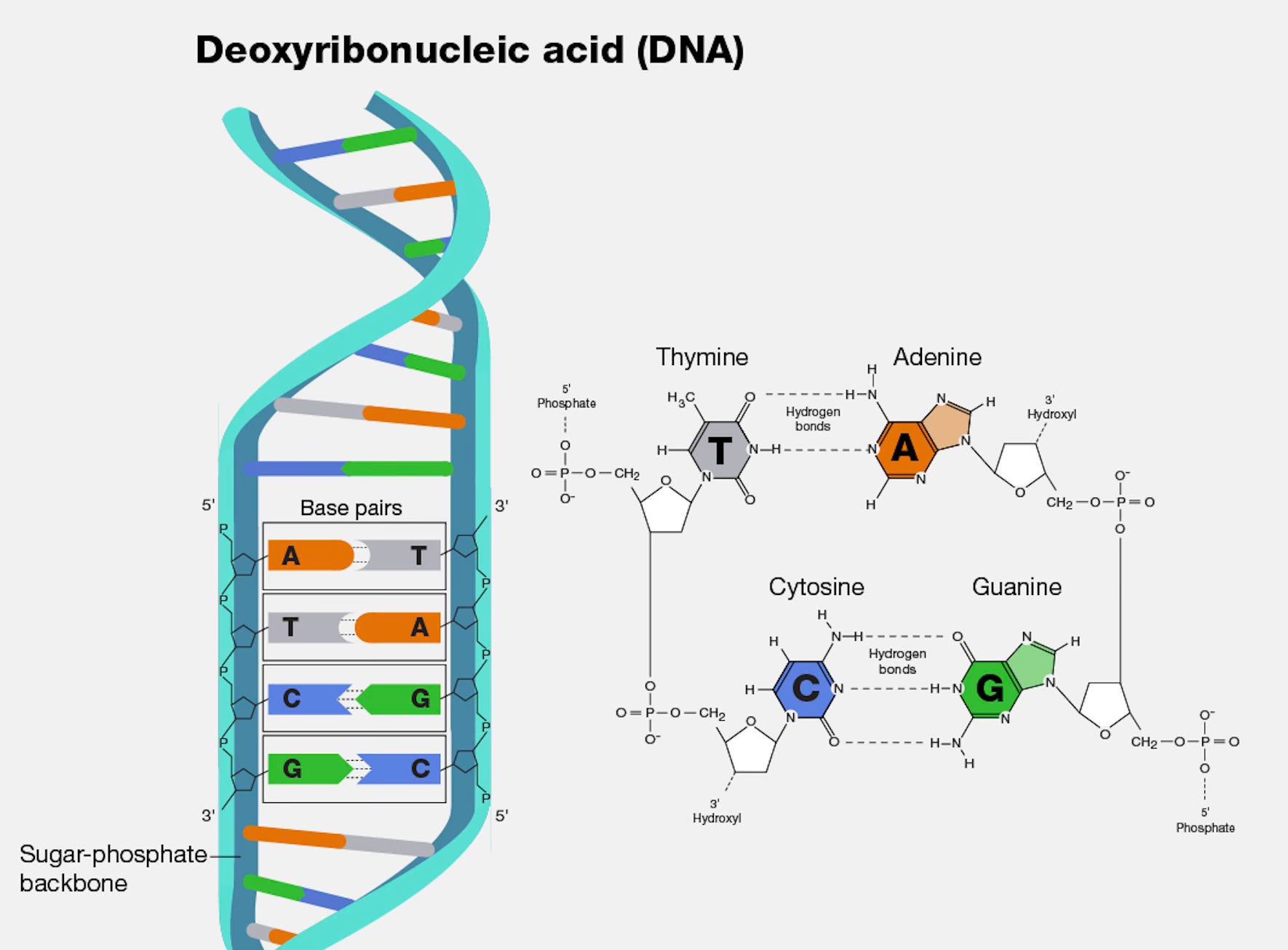
Storing (i.e. synthesizing) and reading (i.e. sequencing) information in and from DNA is not complicated in theory. Each base can store two bits, e.g.: A → 00, T → 01, C → 10 and G → 11. These bases can then in turn be synthesized or sequenced representing a sequence of bits, meaning data.
What makes DNA (in theory) so interesting as disruptive contender is the sheer amount of data that DNA can store given its size. To give two references:
1) All of the existing data on the internet stored in DNA would be the size of a sugar cube, or one cubic centimetre. In comparison, an average tape drive data centre is about one thousand cubic metres in size, of which we have a few thousands scattered across the globe. We’ll get into tape drives later!
2) A single gram of DNA is capable of holding 455 exabytes of data, exceeding the data hold by all of the BigTech giants (Google, Facebook and more) together. For reference: one exabyte corresponds to one billion gigabyte.
But it’s not only the amount of information DNA can hold that makes it interesting, but also for how long it can store information without loss or degradation. If you remember the Greenland example from the introduction, there has been an incident where data was conserved for 2 million years. Of course the conditions are wildly different to what a practical use case would look like, as this was fossilized DNA (i.e. preserved in rock). Nonetheless, this shows the storage potential DNA holds. A recent study suggests a potential lifetime of up to 2000 years in a more practical (but still cumbersome) storage approach by keeping it at 10°C and excluding all water from its environment. In contrast, the average lifetime is 5 years for hard disk drives and 10-20 years for tape drives, resulting in the need for constant replacements just to keep the existing information.
👩🏻🔬 DNA Storage in Practice
While we are able to cheaply sequence large amounts of DNA - with a few laboratories having capacity to sequence over 100.000 billion bases per year - we significantly lag behind in synthesizing. Sequencing has progressed in Moore’s Law like manner, but we are only able to synthesize short pieces of single-stranded DNA (ssDNA) up to a few hundred bases (a few kilobyte of information) via chemical processes at low synthesis speeds. Quite far away from practical use-cases in storage! The figures below from Rob Carlson illustrate progress for both synthesizing and sequencing DNA on a price per base basis in the first diagram and on a productivity (speed times capacity) basis in the second diagram. On a side note: his blog is worth a read if you want to dig deeper.


So what does this mean? Sequencing has reached the engineering stage of technological exploitation, meaning that the fundamental science of sequencing is solved and we currently optimize the process further and further to increase performance. Synthesizing on the other hand is still in its science stage of technological exploration, meaning that we are currently searching for the technology to begin with, by exploring different scientific approaches on how to solve synthesizing in an efficient and effective manner. Thus, progress in sequencing outpaces synthesis by a wide margin.
To make DNA storage work though, we need to find an approach to reliably scale-up synthesizing to a few thousands of bases while simultaneously increasing the synthesizing speed or productivity. Otherwise, the capacity and throughput is just not commercially relevant. In research you can find a few approaches to make this work. One is to fuse biologically occurring enzyme processes with semiconductor technology like in the paper here. Pretty science-fiction, but in this particular case won’t work on a data centre scale as a highly toxic chemical solvent is required. There also exist different techniques to actually store the synthesized DNA. It can be encapsulated in a microscopic sphere of glass, mimicking fossilization as outlined in here by Robert Grass of ETH Zurich. A more sustainable and scalable approach though would be “printing” DNA on paper as outlined here by researchers from Tianjin University. But to be honest, the more common variant as of today would be to just store it in test tubes.
To sum this chapter up, novel approaches in synthesizing are needed for a breakthrough to elevate DNA on commercial scale. In turn this also means that from an investor perspective, synthesizing is the part of DNA storage where opportunity is found. Historically, the failed ventures in the synthesizing businesses were not geared towards storage applications, but to the construction of new genomes. This market did not take-off as expected as the demand in synthesis has grown as much as the price per base has fallen, resulting in no (revenue) growth at all. The market for storage is quite different, so building a product around it might work.
Before we try to answer the question if DNA might be the future of data storage, let’s have a closer look at the actual problem statement of storage and how the future will look like without new approaches and where DNA might have an angle of attack.
If you want to dive deeper into the different techniques to synthesize DNA have a look at this extensive paper in nature, and for sequencing take a look at this publication by the National Human Genome Research Institute.
💽 Current Approaches to Storage
Approaches to storage can be categorized by the different types of data and their use.
Frequently accessed data is labeled as hot data and usually stored on high-performing devices like solid-state drives (SSDs). SSDs are semiconductor based storage devices without any moving parts, making them comparably fast. They are optimized for response times and writing/reading speeds, resulting in high cost per bit. A typical use-case is installing operating systems on SSDs, like Windows or macOS.
Warm data is somewhat less frequently accessed and stored on devices that offer a trade-off between speed and capacity, usually hard disk drives (HDDs). HDDs contain disc-like objects known as "platters," (just think of a CD) where data is stored through an electrical charge which represents a bit. By spinning the platter it is possible to read out sequences of bits which can be translated into binary code. HDDs are used for storing movies, videos and many more use-cases.
Lastly, infrequently accessed data is labeled as cold data and stored on tape drives. Tape drives are based on magnetically reading and writing data onto tape, a long and thin plastic film coated with magnetic material. The data can only be accessed by sequentially going through the whole tape (think of winding up an audio cassette tape). In contrast, HDDs can skip to the place of storage on the platter and SSDs can read the information out directly. This makes tape very slow and cumbersome, but also very cheap. Thus, tape is used for archival and longterm applications like regulatory and legal compliance data, or backups.
The graph below visualizes our data types and compares the likelihood of access (red and green line), the commercial value (blue line) and the volume of data for each type of data. The commercial line clearly points out the value of data resulting from “data-mining” represented by the largest peak, but also the value of longterm and permanently stored cold data. While the data we interact on a regular basis with is the most valuable, archival data makes up the majority (60-80%) of all data that is around. Think of a floating iceberg, where only the small peak is visible.

To complete the picture let’s have a look at how these technologies scale and where we might run into bottlenecks in the future. In the figure below you can find the areal density improvements for HDDs (red) and tape (green) over the last three decades as well as an outlook for tape storage until 2029. SSDs are not included in this graph but their scaling follows a similar pattern to HDDs.
While tape has progressed with a consistent 34% CAGR and is expected to do so for the next years, HDDs (and SSDs alike) significantly slowed down in performance (=density) improvements. Please keep in mind that the Y-axis is logarithmic, so the linear growth you can see is exponential!

What does all of this mean for the future of data storage?
The good news: The (nearly ancient) technology of tape is still going strong for the next years and continues to improve in a Moore’s Law like manner.
The bad news: Our most performant storage technologies suffer from miniaturization limits and their current density improvement rates (below 8%) are nowhere near suitable to face the growth in data (at 20-40%) in a sustainable and economical manner.
Quick side note: You can find very different growth rates in data and the 20-40% CAGR is just a reasonable estimate. It could also way above at 60%. It is very hard to pin it down to a concrete number due to the current dynamics in adjacent verticals like AI. The more important point is that we are very much near, at, or even above our production- and performance-imposed improvement limits.
Where to go from here? It is quite clear that, although tape seems to be ever increasing in performance, the overall current technology stack won’t be able to match the data flooding in the longterm, if our data figuratively continues to explode at 20-40% CAGR or more. The current LLM induced data generation trend might even push this growth to new levels. It might be possible to shift warm data in parts onto tape though, as corporations notoriously store unnecessarily archival data on HDDs. According to ICD and Seagate, 62% of data is stored on HDDs and only 15% on tape in 2021. More or less the opposite of what is expected. But the shifting of data and data growth in conjunction might break our tape capacity longterm, already being responsible to store vast amounts of valuable cold data.
📜 Is DNA the Future of Data Storage?
Now that we have set the stage and an overview of the problem statement and DNA as potential problem solution let’s form this into a thesis.
Speaking from a technological potential point of view, SDDs and HDDs are favorable for replacements simply because of their diminishing returns in improvements. It is just a matter of time until there will be no improvements at all when we reach structural scales of atoms (comparable to compute chips as explained here) where physics suddenly starts to behave funnily and nothing works anymore as engineers would expect (as explained here). Will DNA be an interesting contender for those technologies? Surely not. HDDs and especially SSDs require comparable fast read and write speeds, which DNA simply cannot offer and also will not offer anytime soon due to limitations in sequencing and mainly synthesizing. My guess for a realistic timeline would be >15 years in the future, if we make significant progress in synthesizing and elevate from scientific exploration into engineering exploitation with Moore’s Law-like improvement.
The case that is left for now is cold data and tape drives, which seems to be more suitable for the strengths and weaknesses of DNA. From my point of view, the following is necessary for DNA to be a serious contender:
Most importantly, DNA needs to overcome capacity limits of synthesizing to be somewhat competitive in (longterm) archival storage. A few kilobyte of capacity are simply not enough. If DNA achieves this, it can play out its strengths in longterm storage applications due to its longterm shelf-life. Tape drives must be renewed every 10-20 years and additionally, the newer generations aren’t downward compatible, leading to additional replacement costs over time. Without the necessary requirement for replacement, maintenance and replacement costs will be significantly lower compared to tape. Synthesizing speed is also a concern, but not as important as capacity, as archival storage is characterized by its infrequent access. Archival use-cases would thus be an interesting beach-head application and with increasing speed, other use-cases can be taken up from there. To be realistic though it will all come down to the total cost of ownership (TCO) comparison between tape and DNA. Yes, tape has some technological drawbacks like necessary replacements and yes, DNA can be extremely compact and dense, reducing the physical footprint by orders of magnitude, but tape drives are still on an upward trajectory while DNA is still struggling to find the right technological angle to scale.
So is DNA the future of data storage? I personally would like to see a future where we use biology’s oldest technique to solve our storage problems, but at the time of writing this I struggle to see it. Speaking from a venture perspective, timing is just off and I don’t expect to see a large share of data being stored in DNA in the next 10 years. What I see is more likely to happen is a shift towards more storage on tape from SSDs and HDDs, maybe even through environmentally-motivated incentives like government subsidies, just because tape is so much more energy efficient than the other two. However, tape won’t continue to improve the way it is now forever, and at some point miniaturization limits will also diminish returns for this technology. Perhaps the timing is right for DNA at this point in time.
🏁 Concluding Remarks
For those of you interested in delving deeper into DNA and storage technologies, check out the following articles and good reads:
Tape Storage Might be Computing’s Climate Savior - IEE Spectrum
On-Demand DNA Synthesis in High Demand - Genetic Engineering
And that brings us to the end of the 6th episode of Deep Tech Demystified. I hope you enjoyed this deep-dive into storage technologies and DNA! If you don’t want to miss the next deep tech content drop, click below:
If you are a founder or a scientist that is building in the field of DNA storage, please reach out on Linkedin or via mail (felix@playfair.vc), I would love to have a chat! Cheers and until next time!
Amazing work, thanks for pulling it together.
Besides DNA storage in its different forms - which other alternative paths do you see at the horizon to solve the storage bottleneck?
Why would DNA be particularly well / ill suited for warm / hot storage? What are the trade offs?
Once developed, how can DNA storage be manufactured at scale, productised and integrated into modern data / compute stacks?